
Internship and Co-op as a Triple Capital Investment in Employability
By Swapnil Lokhande
Faculty mentor: Julia Ivy
April 19, 2020
The research involves the analysis of EMPLOYERS’ PERSPECTIVE on the impact of the internship and co-op program on the employability of the students or job seekers. The fundamental analysis in this research involves the identification of the keywords used by the people (authors) while discussing the internship program in their articles published on business-related and business-targeting public platforms. The goal is to analyze the keywords based on the BE-EDGE methodology and see how far the internship program helps the students in developing their Personal Capital, Social Capital, and Professional Capital.
METHODOLOGY FOR DATA SELECTION AND EXTRACTION
Article selection and filtering
For the analysis of the keywords, the main source of data is the publicly available articles related to the internship and its benefit. The analysis of the articles is done in two parts which involve two different datasets – 1. Benefits of Internship 2. Skill development through Internship.
- Benefits of Internship: The articles chosen for this analysis are selected based on the following Google-searched and other recommended articles: “Impact of Internship on Students’ employability, Importance of internship for college students.”
- Skill development through an internship: The articles chosen for this analysis are selected based on the following Google-searched and other recommended articles: “Skills gained from the internship, Benefits of internship in personal and professional development, experience gained during the internship.”
Only those articles are selected which are generic to internship benefits and the skills developed through internships and not specific to a particular internship done in a specific industry or sector such as accounting, software development, or management/consulting, etc. This is done to avoid any biases for an internship done by a student from a specific course or the internship done in a particular industry and thus findings represent a generic result for the internship as a whole.
It was observed that the first 4 pages of the google search gave relevant articles, and after that, the articles were more specific to a particular type of internship or specific to an industry. Thus, only the articles presented on the first 4 pages of the Google search were selected.
Data Extraction Method
In order to analyze the articles and get insights from those articles: extract the content of the articles that are present in the HTML format, store it in a simple text format (CSV or JSON), and use the text for further processing and analysis. Thus, our first approach in this project is to build an application that can be used to extract the desired content from different websites and store the content in the required format, and to accomplish this, a different web scraper is deployed to gather the data.
Web scraper for articles – Purpose and Technique
- Designed a simple web scraper using Python programming that can be used to pull the content from an article.
- In this application, the user needs to pass the URL of an article that is freely available (Example: articles from The Conversation or The New York Times, etc.)
- The application uses requests and the BeautifulSoup package of Python which are used to extract the HTML code from the given article and process it to pull the required content.
Drawback
- Unable to extract the content from the articles which require a mandatory login on to the portal.
METHODOLOGY FOR DATA ANALYSIS AND KEYWORD DETECTION
The main goal of this research is to identify the keywords that are frequently used and are highly relevant to the topics – Benefits of a master’s degree and skills developed through a master’s degree. Thus, to identify such keywords a Machine Learning algorithm for Natural Language processing is used which is TF-IDF (Term frequency and Inverse document frequency). This algorithm is generally used when processing human-readable language and is used to convert words into a numerical format where each word is represented in form of a matrix (Gajare, n.d.)
How to calculate TF-IDF score
TF-IDF for a word in a document is calculated by multiplying two different metrics:
- The term frequency (TF) of a word in a document is a raw count of instances a word appears in a document.
- The inverse document frequency (IDF) of the word across a set of documents. This can be calculated by taking the total number of documents, dividing it by the number of documents that contain a word, and calculating the logarithm. The IDF is calculated to identify how common or rare a word is in the entire document set. The closer it is to 0, the more common a word is, and the more it is closer to 1 shows how rare it is.
Multiplying these two numbers results in the TF-IDF score of a word in a document. The higher the score, the more relevant that word is in that particular document (Stecanella, 2019).
Approach for determining keywords
The TF-IDF score for each bi-gram and tri-gram is calculated. The higher the TF-IDF score, the word is more relevant in that particular document. For the analysis purpose, uni-grams are excluded since these words don’t give much information and thus are discarded. For instance, from a document, we want to find out the skills required to be a “data scientist”. Here, if we consider only unigrams, then the single word cannot convey the details properly. If we have a word like ‘machine learning developer’, then the word extracted should be ‘machine learning’ or ‘machine learning developer’. The words ‘machine’, ‘learning’ or ‘developer’ will not give the expected result (Gajare, n.d.).
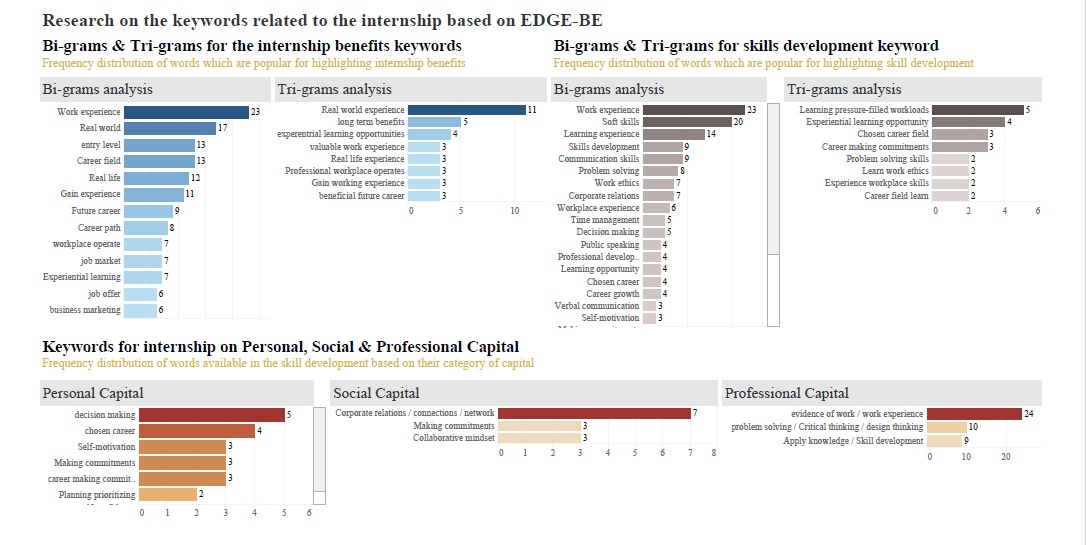
Findings and Result
The result consists of the bi-grams and tri-grams associated with the articles – Benefits of internship and skills development through an internship. The keywords are ordered in the descending order of their rank. Here, rank is the TF-IDF score which shows the importance of the word or relevance of the word in the given article. For example, the keywords “Work Experience” have the highest score as well as the highest frequency since it is assumed that internship provides practical work experience to the students while collaborating with the team in the organization. The keywords are detected using the Tf-IDF score along with their frequency, however, only the frequency of the word is used for further analysis and building dashboards.
Words related to Personal capital
| EDGE Required Words | Other meaning | Alternate words related to the analysis |
| Identity | Self-esteem, individuality | Self-motivation or self confidence |
| Focus | Center of interest or activity | Making commitments, chosen career, decision making |
| Strategy | Plan of action | Planning prioritizing, career making commitments |
Words related to Social capital
| EDGE Required Words | Other meaning | Alternate words related to the analysis |
| Trust | Quality of being true | Not enough evidence found to justify this keyword |
| Empathy | Ability to understand the feeling and share the feelings of others | Making commitments |
| Relationships | The state of being connected | Corporate relations, connections, network |
| Rapport | Understand each other feelings and share ideas | Collaborative mindset (can be indirectly related to rapport) |
Words related to Professional capital
| EDGE Required Words | Other meaning | Alternate words related to the analysis |
| Justification | Action of showing something reasonable | Apply knowledge |
| Proof | Evidence to help establish a fact | Apply skills, evidence of work, ability to show |
| Design thinking (preferably used by designers and design teams) | Cognitive, strategic, and practical processes by which design concepts are developed by designers | Critical thinking, problem solving (most commonly used phrases ) |
The above dashboard is built using the EDGE-BE classified words. The frequency of the words is used to compare words present in different categories. From the above analysis, it can be clearly seen that words having the highest frequency (work experience and critical thinking/problem solving) belong to professional capital. However, the internship program also has an influence on personal and social capital and is very much responsible for developing decision making and choosing a career. It also helps in networking, building connections, making commitments, and developing a collaborative mindset.
Note: The analysis is done on a sample of data and the results may vary if more articles are collected for analysis. Further research and analysis can be performed using other machine learning algorithms for natural language processing to find more accurate results between the words and collaborate and classify words based on their relationship with other words. This can be done to further expand this research in the future.
References:
D’Souza, J. (2018, Apr 3). An Introduction to Bag-of-words in NLP. Retrieved from https://medium.com/greyatom/an-introduction-to-bag-of-words-in-nlp-ac967d43b428
Vivek, S. (2018, Dec 17). Automated keyword extraction from articles using NLP. Retrieved from https://medium.com/analytics-vidhya/automated-keyword-extraction-from-articles-using-nlp-bfd864f41b34
Gajare, S. (n.d.). Tf-Idf for Bi-grams and Tri-grams. Retrieved from https://www.geeksforgeeks.org/tf-idf-for-bigrams-trigrams/
Stecanella, B. (2019, May 10). What is Tf-Idf? Retrieved from https://monkeylearn.com/blog/what-is-tf-idf
About the author

Swapnil Lokhande, Data Science and Advanced analytics practitioner and researcher. A graduate student from Northeastern University, Boston, accomplished by Masters in Analytics. Looking for opportunities to apply my skills in analytics and computer science in delivering business solutions and simultaneously apply my knowledge in research projects. Swapnil has an extensive educational background and multi-dimensional industrial experience which makes me a passionate learner and a problem solver. In the last 5 years of my career, I have learned and developed expertise in delivering data-driven solutions to analyze business trends through statistical and predictive models and effectively communicate the findings and statistical results to technical and non-technical teams using interactive dashboards.
Outside of work, I am passionate about mentoring and teaching emerging engineering students. I have also worked as Assistant Professor in a public university in India and always try to connect with my students to help them learn programming languages using real-world problems, mentor them in their academic projects, and help them make informed decisions in their career path.
